
PHOTO
Il testo che segue è parzialmente tratto dall'intervento a Un digitale deGenere, Conferenza Cgil per il futuro dell’Europa del 15 luglio 2021.
Da quando il mercato è diventato un'etica con le sue manifestazioni di biopotere, i computer sono al centro dei processi di individualizzazione o di personalizzazione tipici del neoliberismo e delle tecnologie governamentali. Il mercato ci vuole isolati, privi di intermediazione, di tutela dei diritti e ci vuole soprattutto "auto-organizzati" e "auto-controllati".
L'innovazione digitale è al centro e attraversa le diverse declinazioni dei piani del Pnrr che il governo italiano ha presentato all'Europa. È l'occasione di chiedere con forza di mettere in condizione la cittadinanza attiva di potersi costituire come un nuovo soggetto di intermediazione fra i singoli individui e l'imponente apparato della governance tecnologica globale che amplifica diseguaglianze e squilibri di potere impedendo l'esigibilità dei diritti di cittadinanza con le sue manifestazioni digitali.
Dietro (e dentro) la produzione di artefatti tecnologici, diffusi su larga scala dall'avvento del capitalismo delle piattaforme digitali (Gafam), c’è un profondo contenuto simbolico che non va ignorato. Le relazioni intersoggettive tendono a essere sostituite dalle relazioni oggettive instaurate dalla circolazione degli oggetti digitali; ancora oggi, essi sono simboli dell’identità maschile oltre che possibilità concrete di comunicazione.
Oggi la scienza algoritmica permette di realizzare sofisticate forme di Intelligenze artificiali che in breve tempo hanno trasformato la comunicazione e lo scambio di informazioni, ma non hanno modificato le relazioni di genere (vedi M. Vaccari, Appunti di femminismo digitale #2 Algoritmi, Amazon Kindle editions, 2021). Mentre le trasformazioni socio-economiche sono state abbondanti e a volte dolorose, il superamento delle questioni di genere è stato considerevolmente più lento e ora rischia di indietreggiare.
Discriminazione digitale
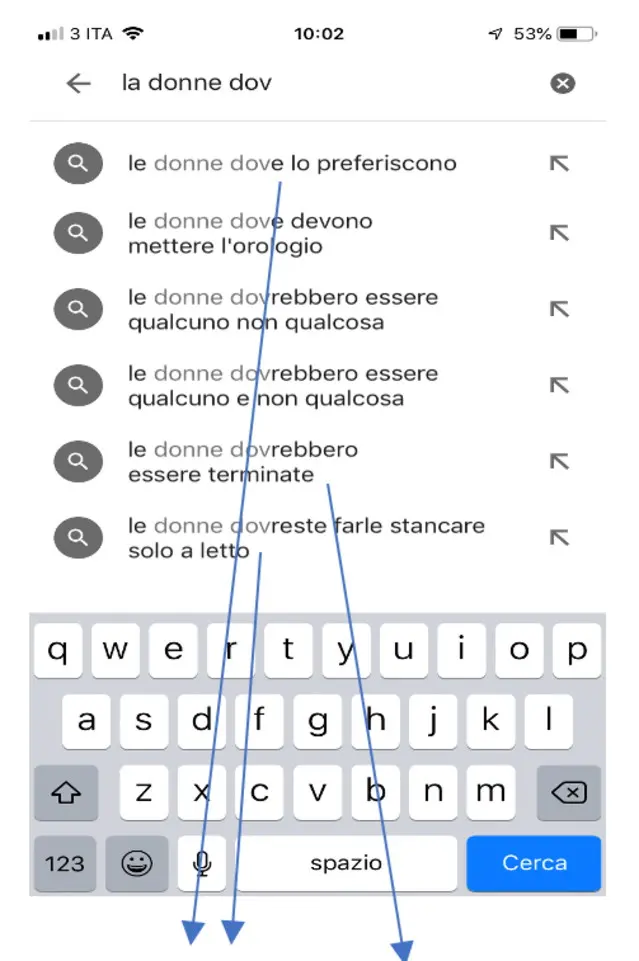
Il bias algoritmico di genere è all'opera prima di tutto nei suggerimenti alla ricerca del completamento automatico di Google (fig. 1) ma in generale nei nostri dispositivi della comunicazione, nel riconoscimento vocale e facciale (per approfondire, vedi M. Vaccari, Google e il sessismo suggerito, 2019, dal blog www.almagulp.it).
Ampiamente utilizzate nelle realizzazioni robotiche con la diffusione dell'AI, fanno emergere nuove forme di discriminazione digitalizzate. Si stima che entro il 2030 saranno acquistati 42 milioni di androidi per uso personale e di cura, ma perché ostinarsi a chiamarli così quando le sembianze umane (fig.2) date alle macchine AI realizzate sono il più delle volte femminili? Sono in realtà delle gineidi (Per approfondire, vedi M. Vaccari, Artificial intelligence, una critica femminista, 2018, dal blog www.almagulp.it).

Con la pervasività delle tecnologie il bias di genere, che nel tempo gli algoritmi hanno mascherato, assume forme e significati che amplificano e diffondono pregiudizi e disparità che si pensavano superati con la presunta raggiunta parità fra i generi. L’algoritmo è la messa in opera di tipo procedurale di un ragionamento a cui seguirà la realizzazione dell’artefatto attraverso il software. Come fare è la domanda e, nei fatti, la riposta si può progettare; è qui che si innesta la presunta estraneità non solo delle donne ma di tutte le differenze, perché il come si fa è operato da una tecnologia del pensiero unico di una scienza troppo spesso universalistica, appannaggio prevalentemente del genere maschile e spesso bianco, occidentale – anglosassone e nordamericano – e agiato.
La rappresentanza femminile nella professione dell’ingegneria dei software in termini globali oscilla dal 3 al 7%, e diventa il 27% solo negli Stati Uniti che è leader mondiale di ingegneria software (Fonte: Evans Data Corporation). C’è un grande scarto di presenze nelle cosiddette discipline Stem, a causa del fenomeno che è stato definito “maschilizzazione” delle scienze dure.
Il bias di genere dipende dai modelli seguiti nella progettazione degli artefatti tecnologici che risentono della sotto-rappresentanza di genere in termini numerici ma anche in termini simbolici in quanto specchio di rappresentazioni stereotipate e piene di pregiudizi. È il cosiddetto dataset training, le informazioni che costituiscono i big data che noi produciamo e che informano l’intelligenza e opera per parametri di comparazione e calcoli predittivi configurati dall'azione umana all'avvio del machine learning, l'apprendimento automatico dell'IA.
Purtroppo l'immaginario culturale e sociale è intriso di discriminazioni di vario tipo che vengono riprodotte dall'IA (Intelligenza artificiale, ndr). Un esempio: nel riconoscimento delle immagini e nel comparare più immagini una IA ha indicizzato l’immagine di un uomo ai fornelli alla voce “donna”. L’indice deriva dall'associazione di cucina-pentola-cibo alla categoria “donna” perché vi sono molte più immagini con questa che con uomini.
Il machine learning riproduce un simbolico discriminatorio attraverso input genuinamente radicati nel sociale e nel politico. I bias algoritmici sono fondati proprio dall’ingegneria delle caratteristiche che funziona con enormi dataset derivati dal nostro utilizzo delle piattaforme: se produciamo dati sessisti l'IA apprende il sessismo. Il problema non è solo tecnologico è politico e culturale e può essere affrontato negoziando altri significati attraverso la realizzazione di artefatti tecnologici che contrastino il potere estrattivo delle principali piattaforme del software finalizzato alla pubblicità personalizzata.
Altri dati e altri algoritmi per le IA
Negli anni della diffusione dell'informatica di massa era predominante la nozione di azione strumentale; oggi le macchine mettono in campo vere e proprie azioni discorsive e mediatiche che dovrebbero rendere possibile negoziati di significato fra gli umani e le macchine. Potrebbe essere un modo per ripensare i concetti di negoziati e di negoziazione riferiti ai modelli di pensiero utilizzati nella produzione algoritmica di artefatti in grado di colloquiare con noi. Insomma, se l’IA avesse dei corpora del parlato, dei testi, delle immagini indicizzate in altra maniera, si comporterebbe diversamente.
Un esempio potrebbe essere il prototipo di un search engine di genere. Reperibile all'indirizzo www.cercatrice.it riguarda le informazioni sulle/per le donne, inerenti a molteplici aree tematiche quali: sicurezza personale, salute, genitorialità; lavoro. Per ricostituire servizi di intermediazione, fra mondo digitale e cittadinanza, si basa sulla localizzazione delle fonti. Utilizza una metodologia gender oriented per il reperimento delle fonti altrimenti invisibili nella Serp, la prima schermata di Google, e attraverso dei metadati semantici come i thesauri evita l'utilizzo dei big data da cui derivano molteplici problemi di privacy e sfruttamento.
Con lo stesso approccio si potrebbe ipotizzare di realizzare un search engine del lavoro. Basato su metadati semantici come i thesauri per il reperimento di fonti di informazione che costituiscono il corpus di riferimento di testi, immagini, video del sindacato attraverso il lessico derivato dal punto vista dei lavoratori, della storia, dalle battaglia per i diritti dei lavoratori, dagli esiti delle contrattazioni eccetera. Un motore di ricerca syndicate oriented che restituisce risposte (pagina Serp) con significati syndicate sensitive.
EuroVoc oppure Eu-Osha potrebbero essere i thesauri con cui iniziare, purtroppo ad entrambi mancano termini descrittivi dell'area digitale ed è necessario molto lavoro di ricerca e di finanziamenti per la realizzazione che potrebbe fornire il Pnrr.
Thesauri, web semantico, search engine potrebbero essere prodotti dal sindacato per contrastare i processi di dis-intermediazione e individualizzazione del Gafam e ambire ad essere soggetto attivo nel mondo digitale con un offerta di artefatti tecnologici che orientano e fanno emergere i diversi punti di vista dei lavoratori.
Marzia Vaccari, docente Media digitali e genere, Unibo




















